How To – SAP HANA Tutorial
La Storia
HANA sta avendo un’adozione senza precedenti da parte dei clienti SAP. SAP HANA è in grado di elaborare una grande quantità di dati in tempo reale in un breve periodo di tempo.
Cos’è Sap HANA?
SAP HANA è il database e la piattaforma in memoria più recenti che possono essere distribuiti in locale o nel cloud. SAP HANA è una combinazione di hardware e software, che integra diversi componenti come il database SAP HANA, il server di replica SAP SLT (System Landscape Transformation), la connessione SAP HANA Direct Extractor e la replica Sybase.
Database e piattaforma SAP HANA
Architettura SAPHANA, landscape, Dimensionamento
- Database SAP HANA: il database SAP HANA è un database in memoria ibrido. Il database SAP HANA è il cuore della tecnologia in-memory SAP. In SAP HANA, le tabelle del database sono di due tipi:
- Row Store
- Archivio colonne
- Piattaforma SAP HANA – La piattaforma SAP HANA è una piattaforma di sviluppo con un archivio dati in memoria che consente ai clienti di analizzare un grande volume di dati in tempo reale. La piattaforma SAP HANA funziona come una piattaforma di sviluppo, che fornisce infrastruttura e strumenti per la creazione di un’applicazione ad alte prestazioni basata su SAP HANA Extended Application Services (SAP HANA XS).
Edizione SAP HANA
Esistono diversi tipi di edizione SAP HANA, alcuni dei quali come di seguito-
- SAP HANA Platform Edition: fornisce la tecnologia di database Core. Integra componenti SAP come database SAP HANA, SAP HANA Studio e client SAP HANA. È per i clienti che desiderano utilizzare la replica basata su ETL e dispongono già di una licenza per SAP Business Objects Data Services.
- SAP HANA Enterprise Edition: contiene il componente di provisioning dei dati (SLT, BODS, DXC) inclusa la tecnologia di database di base. È per i clienti che desiderano utilizzare la replica basata su trigger o la replica basata su ETL e non dispongono di tutte le licenze necessarie per SAP Business Objects Data Services.
- SAP HANA Extended Edition: contiene funzionalità di provisioning dei dati (Sybase) più dell’edizione Platform and Enterprises. È per i clienti che desiderano utilizzare il pieno potenziale di tutti gli scenari di replica disponibili, inclusa la replica basata su log.
Il diagramma seguente mostra la differenza tra tutte le edizioni:

Perché scegliere SAP HANA?
SAP HANA è una piattaforma aziendale in-memory di nuova generazione. Accelera l’analisi e l’applicazione su un’unica piattaforma in-memory.
Di seguito indicati sono i pochi motivi per cui scegliere SAP HANA –
- Tempo reale: SAP HANA fornisce provisioning dei dati in tempo reale e reporting in tempo reale.
- Velocità: SAP HANA fornisce un’elaborazione ad alta velocità su dati di grandi dimensioni grazie alla tecnologia in-memory.
- Qualsiasi dato / origine: SAP HANA può accedere a varie origini dati, inclusi dati strutturati e non strutturati da origini dati SAP o non SAP.
- Cloud: il database e l’applicazione SAP HANA possono essere distribuiti nell’ambiente cloud.
- Semplicità: SAP HANA riduce gli sforzi per il processo ETL, l’aggregazione dei dati, l’indicizzazione e la mappatura.
- Costo: SAP afferma che il software SAP HANA può ridurre il costo IT totale di un’azienda.
- Opzione di scelta: SAP HANA è supportato da diversi fornitori di hardware e software, quindi in base al requisito l’utente può scegliere l’opzione migliore.
Strategia in memoria di SAP HANA
SAP HANA ha molti processi in esecuzione su SUSE Linux Server. Il server SUSE Linux gestisce la prenotazione della memoria per tutti i processi.
All’avvio di SAP HANA, il sistema operativo Linux riserva la memoria per il codice del programma, lo stack del programma e i dati statici. Il sistema operativo può riservare dinamicamente memoria dati aggiuntiva su richiesta dal server SAP HANA.
SAP HANA crea un pool di memoria per la gestione e il monitoraggio del consumo di memoria. Il pool di memoria viene utilizzato per archiviare tutti i dati in memoria e le tabelle di sistema, lo stack di thread, i calcoli temporanei e tutte le altre strutture di dati richieste per la gestione del database.

Quando è necessaria più memoria per la crescita della tabella o calcoli temporanei, il gestore della memoria SAP HANA la ottiene dal pool.
Per una panoramica, controlla la funzionalità Panoramica della memoria dello studio SAP HANA. Per accedervi, fare clic con il pulsante destro del mouse su un sistema -> Configurazione e monitoraggio -> Apri panoramica della memoria nel menu contestuale, come segue:

Vantaggi di SAP HANA
Di seguito sono riportati i vantaggi di SAP HANA:
- Grazie alla tecnologia In-Memory, l’utente può esplorare e analizzare tutti i dati transazionali e analitici in tempo reale da praticamente qualsiasi fonte di dati.
- I dati possono essere aggregati da molte fonti.
- I servizi di replica in tempo reale possono essere utilizzati per accedere e replicare i dati da SAP ERP.
- Interfaccia SQL e MDX da supporto di terze parti.
- Fornisce la modellazione delle informazioni e l’ambiente di progettazione.
Confronto tra SAP HANA e BWA (Business Warehouse Accelerator)
- Acceleratore SAP BW: è un acceleratore in memoria per BW. BWA si concentra sul miglioramento delle prestazioni delle query di SAP NetWeaver BW. BWA è specificamente progettato per accelerare le query BW riducendo il tempo di acquisizione dei dati persistendo le copie dell’infocube.
- SAP HANA: SAP HANA è un database e una piattaforma in memoria per applicazioni e report analitici ad alte prestazioni. In SAP HANA i dati possono essere caricati da SAP e non SAP Source System tramite SLT, BODS, DXC e Sybase e possono essere visualizzati utilizzando SAP BO / BI, Crystal Reports e Excel, ecc.
Attualmente, SAP HANA funziona anche come database in-Memory per SAP BW, quindi in questo modo SAP HANA è in grado di migliorare le prestazioni complessive di SAP Net weaver BW.
Sommario:
- SAP HANA è un database e un’applicazione in memoria, che viene eseguito su hardware e software autenticati da SAP.
- SAP HANA ha tre versioni: piattaforma, aziende ed estesa.
- SAP HANA può caricare dati da origini dati SAP e non SAP tramite SLT, BODS, DXC e Sybase.
- SAP HANA fornisce provisioning e reporting in tempo reale.
- SAP HANA fornisce report analitici in tempo reale ad alte prestazioni.
- SAP HANA riduce i costi IT totali.
Il database SAP HANA è una piattaforma di gestione dei dati incentrata sulla memoria principale. Il database SAP HANA viene eseguito su SUSE Linux Enterprises Server e si basa sul linguaggio C ++.
Il database SAP HANA può essere distribuito su più macchine.
I vantaggi di SAP HANA sono i seguenti:
- SAP HANA è utile in quanto è molto veloce grazie a tutti i dati caricati in memoria e non è necessario caricare i dati dal disco.
- SAP HANA può essere utilizzato ai fini di OLAP (On-line analytic) e OLTP (On-Line Transaction) su un unico database.
Il database SAP HANA è costituito da un set di motori di elaborazione in memoria. Il motore di calcolo è il principale motore di elaborazione in memoria in SAP HANA. Funziona con altri motori di elaborazione come il motore di database relazionale (motore di riga e colonna), motore OLAP, ecc.
La tabella del database relazionale risiede nell’archivio di colonne o righe.
Esistono due tipi di archiviazione per la tabella SAP HANA.
- Archiviazione del tipo di riga (per la tabella di riga).
- Archiviazione del tipo di colonna (per la tabella delle colonne).
I dati di testo ei dati di grafici risiedono rispettivamente in Motore di testo e Motore di grafico. Ci sono altri motori nel database SAP HANA. I dati possono essere memorizzati in questi motori fintanto che è disponibile spazio sufficiente.
In questo tutorial imparerai-
Architettura SAP HANA
I dati vengono compressi mediante diverse tecniche di compressione (ad es. Codifica dizionario, codifica run-length, codifica sparse, codifica cluster, codifica indiretta) nell’archivio colonne SAP HANA.
Quando il limite di memoria principale viene raggiunto in SAP HANA, tutti gli oggetti del database (tabella, vista, ecc.) Non utilizzati verranno scaricati dalla memoria principale e salvati nel disco.
Questi nomi di oggetti sono definiti dalla semantica dell’applicazione e ricaricati nella memoria principale dal disco quando richiesto nuovamente. In circostanze normali, il database SAP HANA gestisce automaticamente lo scarico e il caricamento dei dati.
Tuttavia, l’utente può caricare e scaricare manualmente i dati dalla singola tabella selezionando una tabella in SAP HANA Studio nel rispettivo schema, facendo clic con il pulsante destro del mouse e selezionando l’opzione “Unload / Load”.
SAP HANA Server è costituito da
- Index Server
- Server preprocessore
- Name Server
- Server statistico
- Motore XS
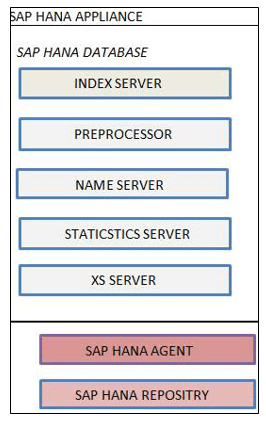
- Index Server SAP HANAIl server principale del database SAP HANA è un server di indicizzazione. I dettagli di ciascun server sono i seguenti:
- È il componente principale del database SAP HANA
- Contiene archivi dati effettivi e il motore per l’elaborazione dei dati.
- Index Server elabora l’ istruzione SQL o MDX in arrivo .
Di seguito è riportata l’architettura di Index Server.

Panoramica di SAP HANA Index Server
- Session and Transaction Manager: il componente Session gestisce sessioni e connessioni per il database SAP HANA. Transaction Manager coordina e controlla le transazioni.
- Processore SQL e MDX: il componente SQL Processor interroga i dati e li invia nel motore di elaborazione delle query, ad esempio SQL / SQL Script / R / Calc Engine. Il processore MDX interroga e manipola i dati multidimensionali (ad es. Vista analitica in SAP HANA).
- SQL / SQL Script / R / Calc Engine: questo componente esegue lo script SQL / SQL e i dati di calcolo vengono convertiti nel modello di calcolo.
- Repository: il repository mantiene il controllo delle versioni dell’oggetto metadati SAP HANA, ad esempio (visualizzazione attributi, visualizzazione analitica, procedura memorizzata).
- Livello di persistenza: questo livello utilizza la funzionalità incorporata “Disaster Recovery” del database SAP HANA. Il backup viene salvato al suo interno come punti di salvataggio nel volume di dati.
- Server preprocessore
Questo server viene utilizzato nell’analisi del testo ed estrae i dati da un testo quando viene utilizzata la funzione di ricerca.
- Name Server
Questo server contiene tutte le informazioni sul panorama del sistema. Nel server distribuito, il server dei nomi contiene informazioni su ogni componente in esecuzione e la posizione dei dati sul server. Questo server contiene informazioni sul server su cui esistono i dati.
- Server di statistica
Il server di statistica è responsabile della raccolta dei dati relativi allo stato, all’assegnazione / consumo delle risorse e alle prestazioni del sistema SAP HANA.
- XS Server
XS Server contiene XS Engine. Consente ad applicazioni e sviluppatori esterni di utilizzare il database SAP HANA tramite il client XS Engine. L’applicazione client esterna può utilizzare HTTP per trasmettere dati tramite il motore XS per il server HTTP.
Panorama di SAP HANA
“HANA” significa High Performance Analytic Appliance è una combinazione di piattaforma hardware e software.
- A causa del cambiamento nell’architettura del computer, il computer più potente è disponibile in termini di CPU, RAM e disco rigido.
- SAP HANA è la soluzione per i colli di bottiglia delle prestazioni, in cui tutti i dati vengono archiviati nella memoria principale e non è necessario trasferire frequentemente i dati dall’I / O del disco alla memoria principale.
Di seguito sono riportate le innovazioni SAP HANA nel campo dell’hardware / software.

Esistono due tipi di archivi dati relazionali in SAP HANA: archivio righe e archivio colonne.
Row Store
- È uguale al database tradizionale, ad esempio (Oracle, SQL Server). L’unica differenza è che tutti i dati vengono archiviati nell’area di archiviazione delle righe nella memoria di SAP HANA, a differenza di un database tradizionale, in cui i dati sono archiviati nel disco rigido.
Archivio colonne
- L’archivio colonne è la parte del database SAP HANA e gestisce i dati in modo colonnare nella memoria SAP HANA. Le tabelle delle colonne vengono memorizzate nell’area di archiviazione delle colonne. L’archivio colonne fornisce buone prestazioni per le operazioni di scrittura e allo stesso tempo ottimizza l’operazione di lettura.
Prestazioni operative di lettura e scrittura ottimizzate con due strutture dati di seguito.

Memoria principale
La memoria principale contiene la parte principale dei dati. Nella memoria principale, viene applicato un metodo di compressione dei dati adeguato (codifica dizionario, codifica cluster, codifica sparse, codifica lunghezza di esecuzione, ecc.) Per comprimere i dati con lo scopo di risparmiare memoria e velocizzare le ricerche.
- Nella memoria principale le operazioni di scrittura sui dati compressi saranno costose, quindi le operazioni di scrittura non modificano direttamente i dati compressi nella memoria principale. Tutte le modifiche vengono invece scritte in un’area separata nell’archiviazione di colonne nota come “Archiviazione delta”.
- Lo storage Delta è ottimizzato per un’operazione di scrittura e utilizza la normale compressione. Le operazioni di scrittura non sono consentite sulla memoria principale ma sono consentite sulla memoria delta. Le operazioni di lettura sono consentite su entrambi gli archivi.
Possiamo caricare manualmente i dati nella memoria principale tramite l’opzione “Carica in memoria” e Scarica i dati dalla memoria principale con l’opzione “Scarica dalla memoria” come mostrato di seguito.

Archiviazione Delta
L’archiviazione delta viene utilizzata per un’operazione di scrittura e utilizza la compressione di base. Tutte le modifiche non salvate nei dati della tabella delle colonne archiviate nella memoria delta.
Quando si desidera spostare queste modifiche nella memoria principale, utilizzare “operazione di unione delta” da SAP HANA studio come di seguito:

- Lo scopo dell’operazione di unione delta è spostare le modifiche, raccolte dall’archiviazione delta all’archiviazione principale.
- Dopo aver eseguito l’operazione di unione delta sulla tabella delle colonne sap, il contenuto della memoria principale viene salvato su disco e la compressione viene ricalcolata.
Processo di spostamento dei dati da Delta alla memoria principale durante l’unione delta

C’è un buffer store (L1-Delta) che è l’archiviazione di righe. Quindi in SAP HANA, la tabella delle colonne si comporta come un archivio di righe a causa di L1-delta.
- L’utente esegue la query di aggiornamento / inserimento sulla tabella (l’operatore fisico è istruzioni SQL.).
- I dati vanno prima a L1. Quando L1 sposta ulteriormente i dati (L1- Dati non confermati)
- Quindi i dati vanno al buffer L2-delta, che è orientato alla colonna. (L2- Dati impegnati)
- Quando il processo L2-delta è completo, i dati vanno alla memoria principale.
Pertanto, l’archiviazione delle colonne è ottimizzata per la scrittura e per la lettura grazie rispettivamente a L1-Delta e all’archiviazione principale. L1-Delta contiene tutti i dati non salvati. I dati impegnati vengono spostati nel negozio principale tramite L2-Delta. Dall’archivio principale i dati vanno al livello di persistenza (la freccia che indica qui è un operatore fisico che invia l’istruzione SQL nell’archivio delle colonne). Dopo l’elaborazione dell’istruzione SQL nell’archivio colonne, i dati vengono trasferiti al livello di persistenza.
Ad esempio, di seguito è riportata una tabella basata su righe

I dati della tabella vengono memorizzati su disco in formato lineare, quindi di seguito è riportato il formato in cui i dati vengono archiviati su disco per la tabella di riga e colonna
Nella memoria SAP HANA, questa tabella è archiviata in Row Store su disco come formato –
![]() Indirizzo di memoria
Indirizzo di memoria
E in Colonna, i dati vengono archiviati su disco come –
![]() Indirizzo di memoria
Indirizzo di memoria
I dati vengono memorizzati in base alla colonna nel formato lineare sul disco. I dati possono essere compressi mediante tecnica di compressione.
Quindi, l’archivio colonne ha un vantaggio nel risparmio di memoria.
![]()
Dimensionamento SAP HANA
Il dimensionamento è un termine utilizzato per determinare i requisiti hardware per il sistema SAP HANA, come RAM, disco rigido e CPU, ecc.
Il principale componente di dimensionamento importante è la memoria e il secondo componente di dimensionamento importante è la CPU. Il terzo componente principale è un disco, ma il dimensionamento dipende completamente dalla memoria e dalla CPU.
Nell’implementazione di SAP HANA, una delle attività critiche è determinare la dimensione corretta di un server in base ai requisiti aziendali.
SAP HANA DB differisce nel dimensionamento con il normale DBMS in termini di:
- Requisito di memoria principale per SAP HANA (il dimensionamento della memoria è determinato dai metadati e dai dati di transazione in SAP HANA)
- Requisiti CPU per SAP HANA (la CPU di previsione è stimata non accurata).
- Requisito di spazio su disco per SAP HANA (viene calcolato per la persistenza dei dati e per la registrazione dei dati)
La CPU del server delle applicazioni e la memoria del server delle applicazioni rimangono invariate.
Per il calcolo delle taglie SAP ha fornito varie linee guida e metodi per calcolare la taglia corretta.
Possiamo usare il seguente metodo-
- Dimensionamento tramite report ABAP.
- Dimensionamento tramite DB Script.
- Dimensionamento utilizzando Quicksizer Tool.
Utilizzando lo strumento Quicksizer, i requisiti verranno visualizzati nel formato seguente:


{kind=link}